ACL 2023 Peer Review Report
There were many new initiatives for peer review at this ACL’23, and we present our report on how all this worked. For the first time, it became an official part of the proceedings - so as to provide context for the final program and to make it easier for future chairs and organizers to find this data. The goal is also to improve transparency in the decision process.
The full report is accessible in ACL Anthology as a part of proceedings: PDF
Here’s a brief guide to what’s in the report:
- What were the acceptance rates for different tracks, and for direct vs ARR submissions? (Section 2); TLDR: ARR submissions had a considerably higher acceptance rate in many tracks.
- How many resubmissions did ACL’23 have, and what happened to them? (Section 3); TLDR: Only 15% of ACL submissions were resubmissions.
- What is the distribution of the ACL author and reviewer pool per country, gender and affiliation types (e.g. faculty, industry, PhD student)? (Section 4); TLDR: we still have work to do to improve gender balance and need to work harder to recruit more reviewers in China.
- What did we do to improve peer review quality? (Section 5); TLDR: we did reviewer tutorials, paper-reviewer matching by Area-Contribution-Language, structured flagging of issues with reviews for the authors, reviewer discussion. We also include community feedback for these features. A highlight: with our paper-reviewer matching approach, 84.97% of the reviews were done by reviewers who expressed interest in the paper contribution type, and 63.58% of reviews for papers targeting at least one language other than English, had a reviewer competent in those languages.
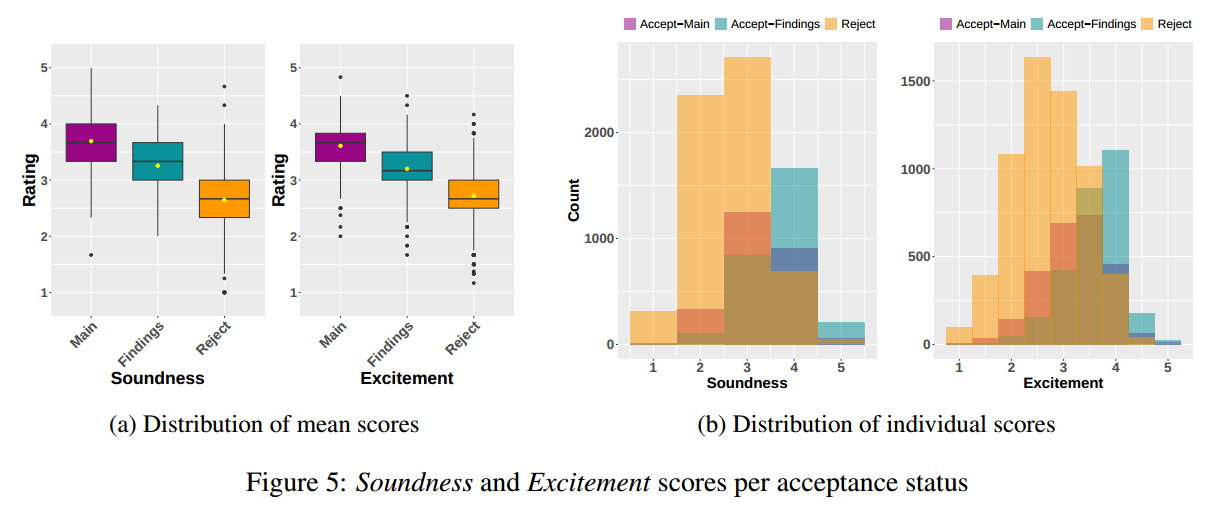
- What did we do to improve decision support for the chairs? (Section 6); TLDR: we revised AC/SAC guidelines, tried to facilitate the checking of automated reviewer assignments, introduced Excitement/Soundness scores in place of Overall Recommendation, and, thanks to the Area-Contribution-Language matching, we were able to provide the chairs with explanations for specific paper-reviewer matches, which served as a useful context for a given review.
- How did we handle ethics review and best paper selection? (Section 8)
- What did we do to improve incentives for peer review? (Section 9)
- For the authors - we made the Responsible NLP Checklist public as a special appendix to the published paper.
- For the program chairs - we established a precedent for publishing an extended report on peer review as part of the conference proceedings, so that we may continually analyze peer review data and learn from our mistakes.
- For the reviewers and area chairs - we introduced new awards for outstanding reviewers and area chairs (the prize is a free virtual registration for an *ACL conference of awardees’ choice within a year of award - so the awardees get to attend more events even if they don’t have a paper there).
And now - the cool stuff! We did a LOT of analysis on what factors contribute to peer review outcomes. Most of it in section 7 of the report. Here are a few highlights for you:
Scores and recommendations:
- How do reviewer scores, AC and SAC recommendations impact the final decisions?
They all do have an impact, but in that order (scores < AC < SAC). Since only SACs implement acceptance quotas, it is possible for papers to be rejected with high scores and positive meta-reviews (sec. 7.2). - Do reviewer confidence scores reflect their (self-reported) experience?
Unfortunately, no (sec. 7.5.3). - Do the reviewer scores correlate with the length of reviews?
The length of reasons to accept/reject does correlate with Soundness/Excitement scores in the expected direction (sec. 7.5.4). - Are the reviewer scores consistent with other reviewers?
No. The Krippendorff’s alpha for scores from 3 reviewers is about 0.3 for both our scores and the usual overall recommendation scores at the recent EACL and EMNLP. But ACL’23 Soundness has a considerably higher raw agreement than Excitement!
What does Area-Contribution-Language paper-reviewer matching help with?
- What is the acceptance rate for the papers with non-mainstream contribution types?
Given our reviewer pool and Area-Contribution-Language, the acceptance rates for different non-mainstream contribution types were mostly higher than for “NLP engineering”! E.g., even though there were no dedicated tracks for efficiency and approaches for low-resource settings, these types of contributions were at least as welcome as mainstream performance-oriented work (sec. 7.3.2). - Does better Area-Contribution-Language matching improve reviewer confidence?
The matches by topic area do (sec. 7.5.1.) - Does better Area-Contribution-Language matching improve reviewer engagement (higher number of review edits or forum posts)?
The matches by contribution do. (sec 7.5.2)
Author-flagged issues with review quality:
- When do authors report review issues?
Authors complain the most about the reviews with low scores and long list of reasons to reject. When reviewers are matched by (non-English) target language, this decreases the likelihood of review issues by 1.29. (sec. 7.5.5) - What review issues do the authors report the most often?
The “lazy thinking” heuristics such as “too simple”, “not SOTA” etc, discussed in our blog post (sec. 5.3. - Do we have problematic individual reviewers?
Yes, but not many. Most reviewers whose reviews got flagged by the authors received only one flag. There are 6.2\% problematic reviewers in our pool, if we consider those with 2+ flags, and only 1.2% (50 reviewers), if we consider those with 3+ flags. (sec 7.5.6)
Preprints effect
- Can the reviewers tell who the authors are?
To a large degree yes. Of all papers that had preprints, the community identified 49% of them. (sec 7.5.7) - Do preprinted papers receive higher scores?
Yes. Soundness, Excitement, and even reviewer confidence scores are all statistically significantly higher for preprinted papers, and they also get recommended for awards at a higher rate. - Does the same happen based on guessing the authors from the content of the paper?
Yes, to a smaller degree. Papers systematically receive higher scores for Excitement, Soundness and confidence even if the reviewers only believe that they guessed the identity of the authors from the content of the paper. Such “guesstimates” are thankfully relatively rare (only 4.1% of reviews), but they do suggest that social effects are at least a part of the explanation for the higher recommendations for preprints (although we are not saying that it is the only factor). (sec 7.5.8) - Is the current 1-month embargo policy working?
Yes, in the sense that the amount of preprints is not zero, but not very high. Preprints were reported for 13.8% of direct submissions to ACL’23. (sec 7.5.8)