ACL 2023 Acceptance Recommendations
One of frequent complaints at the past conferences was that solid work was rejected for not being “surprising”/”novel”/”too niche”/etc, based on reviewers’ rather subjective views. This is difficult to combat because in a system in which the reviewer provides a single recommendation score, such subjective preferences are inevitably tangled with judgements on the other aspects of the paper.
ACL’23 is experimenting with an alternative paper scoring system. Instead of the traditional “overall recommendation” score, we explicitly ask reviewers about whether the submission presents sound research, and how exciting they personally find it. The former criterion can be estimated more objectively, as long as the reviewers have sufficient expertise. The latter is inevitably more subjective, and may reflect the reviewers’ own research agenda, perception of novelty, potential utility to themselves or their sub-community, or other such factors that are hard to disentangle – but reviewers do wish to communicate. You can see the full form and its scoring rubrics here.
The pros of this separation of “soundness” and “excitement” are as follows:
- the reviewers should be able to provide more accurate estimates of soundness by disentangling their own research interests and preferences;
- the reviewer job is easier (especially the new reviewers, who may not have a very clear idea of what is expected of an *ACL paper, could find it hard to make that call);
- the authors receive more actionable information from the review: e.g. instead of overall score “3” you get “2” in soundness and “4” in excitement, you know that you need to revise and resubmit, and if it’s the other way round - then you just were not lucky to find a reviewer who shares your interests;
- the authors can focus their response on soundness (where reasonable argumentation is possible) rather than excitement (where it may not be very productive to try to convince the reviewers that their research tastes are wrong);
- the chairs have more information for assembling the program and planning the conference sessions;
- through correlating these scores with paper types,we can learn the implicit and explicit norms and attitudes in the field to improve the peer review process.
One complaint we’ve seen on social media is that the old system of an overall score offered a better clue as to whether a paper is going to get in and are disappointed because they don’t see such a straightforward mapping here. However, even the regular “overall recommendation” could only be trusted for the relatively few papers with all top scores or all low scores. In the middle, much is at the discretion of the chairs, who rely on the full review text, consider reviewer confidence and expertise, etc. It’s the same in our case, except that the chairs get a bit more information to go on. Our hope is that this information will help chairs come to better conclusions.
Let’s dig into this a bit more:
- neither score is functionally equivalent to the traditional “overall recommendation” score (unfortunately, softconf shows statistics for only one of them in the review reports, but that does not mean it’s the same as the old score);
- the “soundness” score is more important: non-scientifically-sound papers should not be published anywhere. This follows from our CFP and common sense. (Some reviewers saw early review reports that highlighted excitement scores but not soundness thought that meant excitement is more central to accept/reject decisions; this is certainly not the case. This was just a symptom of Softconf catching up to the new review criteria, and it is now fixed.)
- the “excitement” score helps decision makers understand reviews better. In conferences using a single recommendation score, a paper with three middling scores is difficult to make a decision about. In ACL’23, if such a paper scores high on soundness but low on excitement, it’s clear that it should be accepted somewhere. If the soundness scores are all low but some reviewers are excited, this probably means the paper is a great idea but needs more development. That said, as in any conference, the chairs have discretion based on their high-level knowledge of the field and editorial priorities. They may also downweigh or discard reviews that have serious issues, low reviewer confidence, etc.
The primary purpose of the author response period is always to clarify any misunderstandings and to improve the accuracy of the reviews. It is the same in our case. We recommend to focus on soundness, because it is realistically the score that is more likely to be improved through clarifications, than “this is not surprising” kind of comments. That said, the authors are of course welcome to address any reviewer points that they wish. An additional quality assurance step that is new at ACL’23 is that the authors can flag serious issues in reviews by their type for the chairs.
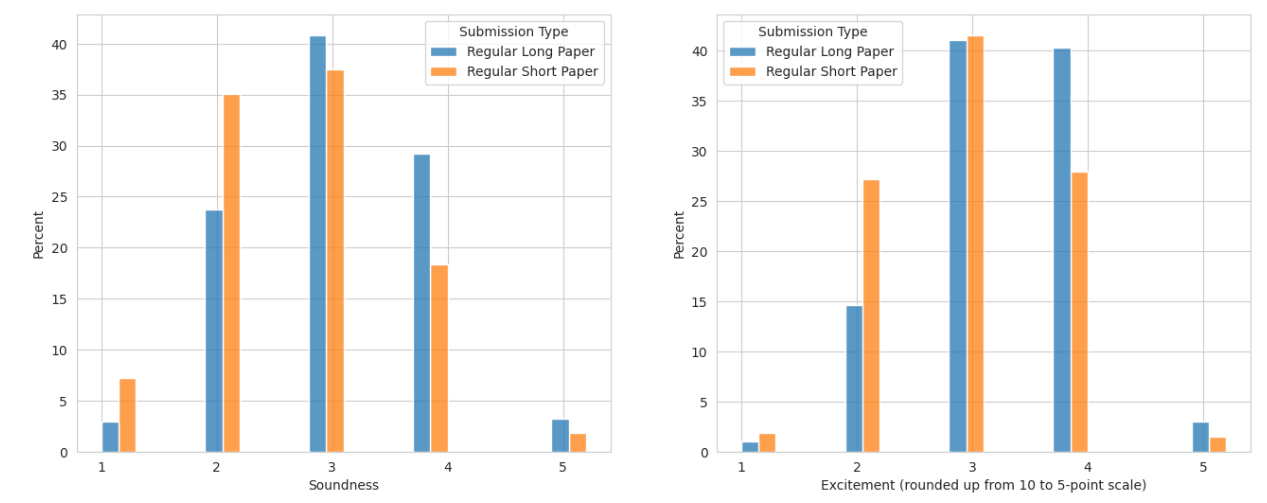
We recognize that this is new and different. It’s an experiment. Thus, to help everyone better understand what’s going on, we are sharing the distribution of the “excitement” and “soundness” scores below. As you can see, most submissions are in the middle of the distribution, just like with the regular single-score process.
FAQ
Q: The “soundness” score less granular than “excitement”, could we add .5 increments?
A: That’s a good idea to improve the system in the future, but at this point it is too late to change the scale, because we cannot guarantee that all reviewers will revisit their scores.
Q: Some people may have misinterpreted “soundness” and/or “excitement” as something else, and rate based on that interpretation.
A: This absolutely is possible (in particular, soundness may be evinced through concepts like clarity and comprehensiveness). But this is also the fundamental problem with the usual “overall recommendation”, which everybody also interprets in very different ways. We hope that our questions are still an improvement in concreteness over the single-score questions, and can be further improved on.
Q: The “soundness” scale skewed: 2 is “borderline”, and “good” is 3, but its description is perhaps more fitting for 4?
A: If the whole scale is skewed, all papers are affected the same, it’s just that the average score will be lower than usual. But this gives us more granularity at the positive end of the spectrum, where we hope that the bulk of the papers would be.
Q: Since it can be challenging to fully assess the correctness and soundness of complex techniques, the “soundness” scores may be biased towards technically lighter papers.
A: This is a possibility, and we will need to do some analysis of low-scoring papers to see if that is the case. But one more relevant aspect here is clarity: if the paper is technically more complex, but manages to explain their method more clearly than other complex papers, “soundness” metric will reward that - and that is arguably a good thing, since it likely correlates with potential impact.